Monitoring di llama.cpp con Prometheus e Grafana...
Un tentativo poco riuscito
Introduzione — Sperimenta in piccolo, sogna in grande
Da qualche mese uno dei mini PC nel mio homelab sta subendo un po’ di maltrattamenti o, per meglio dire, sta venendo utilizzato un po’ oltre quelle che erano le sue specifiche di utilizzo atteso. Gli faccio fare cose per cui non è stato progettato: caricare LLM, processare prompt, generare testo e analizzare immagini. Roba da PC serio, con GPU discreta insomma, ma lui non lo sa e funziona lo stesso.
Eppure, questo piccolo Minisforum X400 con il suo Ryzen 5 4650G Pro, 32GB di RAM e la sua GPU integrata da 7 CU se la cavano non male considerando tutto. Non è un fulmine di guerra — per darvi un’idea, con Qwen3.6 35B A3B in quantizzazione a 4 bit viaggia sui 70-80 token al secondo in prefill e circa 12 token al secondo in generazione. Non proprio da gridare al miracolo, ma è veramente incredibile pensare che una macchina del genere possa far girare un modello con capacità perfettamente sufficienti per piccoli task nel campo dell’automazione domestica, ad esempio.

Con un coding agent leggero come pi e grazie alla magia della KV cache, piccoli task si gestiscono. Anche per workflow batch più strutturati — ad esempio un paio di automazioni implementate con n8n per sfruttare le capacità multimodali del modello — non ha nessun problema e svolge egregiamente il suo lavoro.
Ovviamente, viste le limitazioni, per lo più mi è utile per sperimentare lato configurazioni e infrastruttura. Difficilmente si può trovare un caso d’uso concreto, con un utente dall’altra parte dello schermo disposto ad aspettare dai 30 secondi ai 5 minuti, per avere una risposta. Eppure l’idea di avere un piccolo inference server locale mi attirava, così ho deciso di usare quello che avevo al momento per mettere a posto il setup e la configurazione, scegliere il backend più adeguato, trovare la configurazione migliore per un paio di modelli e poi spostare tutto su una macchina più performante una volta disponibile.
Una delle cose che particolarmente mi interessa del mio setup, è l’osservabilità e la capacità di monitorare come variano le prestazioni del sistema a fronte di diverse configurazioni, feature e modelli. Nello scenario di oggi, in cui escono nuovi modelli di frequente e dove bisogna destreggiarsi fra diversi tipi di speculative decoding, gestione della quantizzazione dei modelli, quantizzazione della cache e la gestione dell’attenzione, avere la capacità di osservare l’impatto sulle prestazioni e la qualità del modello delle diverse configurazioni è fondamentale: senza dati, sei cieco.
L’osservabilità e i dati sono la chiave per poter prendere qualsiasi decisione in maniera informata. Tutto quello che non è supportato da un numero, un grafico, un’evidenza concreta, è solo un’impressione. E in quanto tale, non può guidare un processo di scelta in ambito tecnico.
Questo post è la storia di come ho cercato di rendere visibile quello che succede dentro llama.cpp. Una storia fatta di metriche, dashboard — e di un bug che, almeno per ora, mi ha costretto a mettere tutto in pausa.
Da llama-swap a llama.cpp
Fino a poco tempo fa usavo llama-swap per gestire i modelli. Per chi non lo conosce, llama-swap è un layer di astrazione sopra llama.cpp che permette di configurare più modelli e gestirne automaticamente il caricamento e la messa a riposo in base alle richieste. Tutto questo molto prima che llama.cpp implementasse la sua router mode nativa.
Llama-swap ha un grande pregio: un’interfaccia web che mostra le prestazioni di ogni singola chiamata — token elaborati, velocità di prompt processing, velocità di generazione, tempi medi per percentili. Tutto bello, tutto visibile, tutto out of the box.
Tuttavia ha anche dei limiti. Il primo: il versioning. Non sono mai riuscito a capire esattamente quale versione di llama.cpp fosse inclusa nelle immagini Docker distribuite da llama-swap. Certo, avrei potuto buildare l’immagine da solo, ma c’era un’altra limitazione più sostanziale: la gestione delle richieste parallele su modelli differenti. Per via di un limite implementativo, llama-swap non riesce a emulare la capacità nativa di llama.cpp di gestire più richieste su modelli diversi contemporaneamente.
Nella mia configurazione attuale questa non è una limitazione ma, come anticipato, questa configurazione è solo il banco di prova per nuovo ferro che è già sulla via, quindi ho deciso di passare oltre e usare direttamente llama.cpp. Così facendo l’obiettivo era di ottenere accesso immediato alle nuove versioni disponibili, con una gestione questa volta chiara del versionamento e senza layer intermedi ad aggiungere potenziale complessità e punti di fallimento per il sistema di inferenza. Tuttavia da subito ho sentito la mancanza del monitoring che llama-swap offriva, anzichè avere una comoda dashboard web da consultare, adesso ero tornato a guardare i log per cercare di recuperare una frazione degli stessi dati che avevo prima.
Prometheus, Grafana ed un software sicuramente non ancora Enterprise Ready
Lo Stack: Prometheus e Grafana
Così mi sono messo al lavoro con l’obiettivo di replicare quello che avevo con llama-swap, ma con strumenti standard. Ho voluto evitare di utilizzare un altro layer intermedio, come ad esempio LiteLLM, per tenere il più semplice possibile la gestione e la configurazione del sistema. Così ho scelto Prometheus per la raccolta, Grafana per la visualizzazione un piccolo script python che fa da collante fra i due, il tutto è documentato nel dettaglio in questo gist GitHub.
La dashboard finale — almeno nelle intenzioni — doveva mostrare:
- L’andamento della velocità di prefill e generazione per modello attivo, con filtro per modello
- I token processati e il tempo cumulativo di elaborazione
- Il numero di richieste concorrenti attualmente attive
- I modelli caricati in memoria
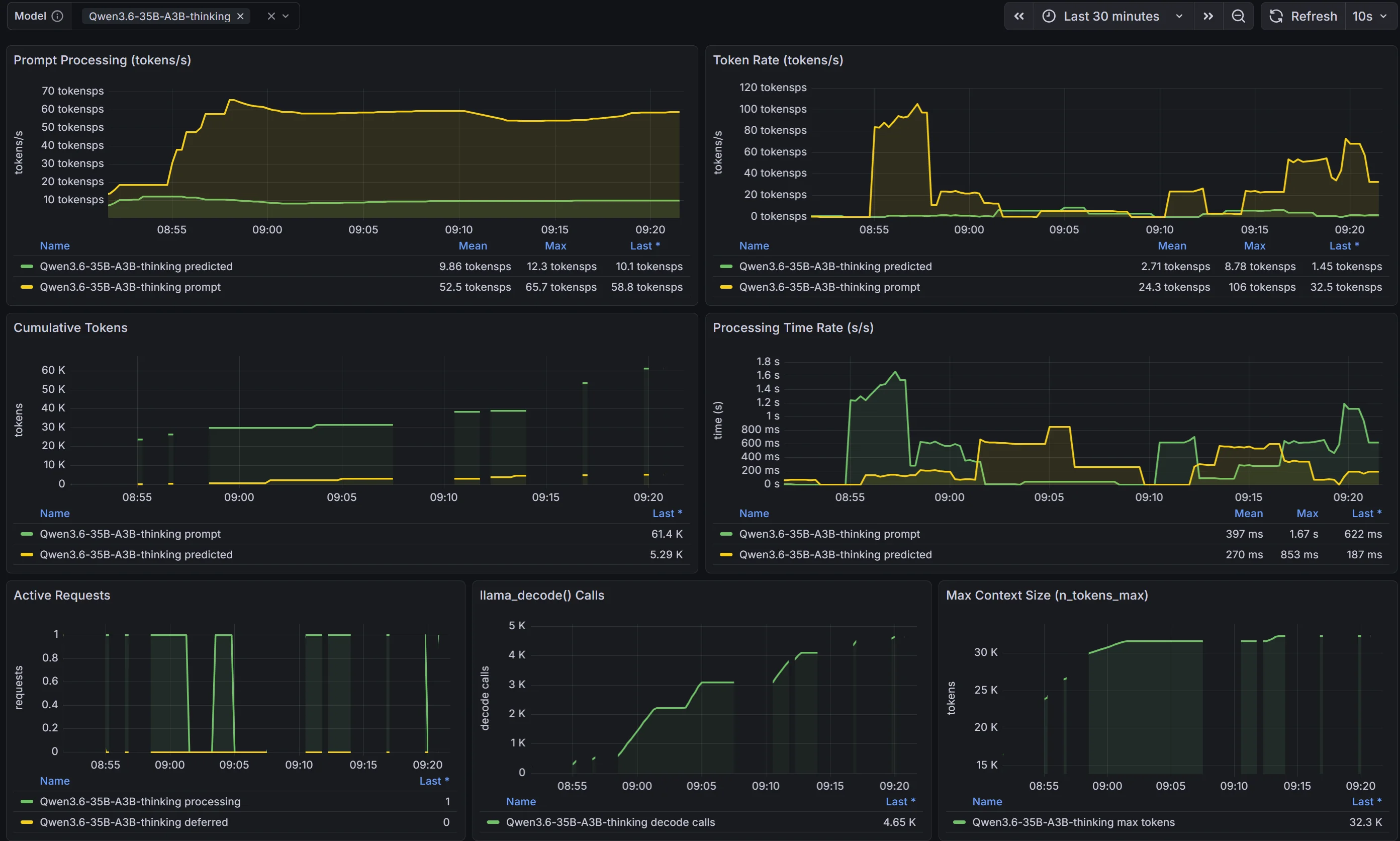
Il problema dello scraper
La prima difficoltà è arrivata subito. llama.cpp espone un endpoint /metrics, ma va chiamato filtrato per modello. Questo significa che non puoi semplicemente puntare un Prometheus vanilla su quell’endpoint e aspettarti che funzioni. Serve uno strato intermedio — uno scraper dedicato che gestisca la logica di filtro per modello.
Niente di insormontabile, ma è stato il primo segnale che la strada non sarebbe stata tutta in discesa.
Il bug che ha fermato tutto
Purtroppo, dopo aver messo in piedi tutta l’infrastruttura — Prometheus che raccoglie, Grafana che visualizza, la dashboard che finalmente prende vita — mi sono scontrato con un muro.
Un bug noto di llama.cpp relativo all’esposizione delle metriche impedisce ai modelli caricati di entrare in idle state, prevenendo sia il risparmio energetico che il cambio di modello a run time in base alle richieste, di fatto rendendo inutilizzabili le funzioni di routing di llama.cpp.
In parole povere: ogni chiamata all’endpoint /metrics resetta il timer di keep alive del modello. llama.cpp pensa che il modello sia ancora in uso, e quindi non libera la memoria quando potrebbe andare in idle.
Le conseguenze sono due, entrambe dolorose:
- spreco di risorse — il modello resta in memoria anche quando nessuno lo sta usando
- il routing non funziona — se il modello caricato è percepito come in uso, llama.cpp non lo libera per fare posto a un altro modello quando arriva una richiesta diversa
Così, per ora, la soluzione è in pausa. La dashboard è lì, i dati ci sarebbero, ma non posso rinunciare alla funzionalità di routing.
Conclusione — anche una sconfitta è un dato
Llama.cpp è un progetto fantastico, in evoluzione rapidissima, ma come ogni software in fase di crescita ha le sue crepe. Terrò la mia dashboard da parte per quando il bug sarà risolto, quando avrò il nuovo hardware, o quando troverò un workaround. Probabilmente, fino ad allora mi affiderò a LiteLLM per monitorare le prestazioni e l’uso del motore di inferenza e dei vari modelli.
Il setup completo è documentato nel gist — se qualcuno vuole seguire la stessa strada (o aiutarmi a trovare una soluzione al bug), è tutto lì.